概述
家庭环境,这里特指中国大陆家庭拨号上网环境,首先是80与443端口都是不通的,要想实现https,配置相对比较麻烦。
- 1、如果拨号环境没有公网ip或要用443端口,也就是没法通过默认的https端口实现加密访问,就需要使用frp之类的服务将内网的nextcloud映射出去。
- 2、如果有公网ip,可以端口映射使用非80/443端口,例如9988端口等映射出去。
关联视频1:https://youtu.be/deA0M1zedlI
考虑到网盘需要较高的安全性,毕竟是隐私数据,不能接受被入侵,就一定要开启ssl证书访问。
如果你已经在内网nas搭建好了nextcloud,就直接直接到frp中转部分或者端口映射部分。
如果没有搭建nextcloud,链接如下:
要想实现https服务的前提是把nextcloud服务映射到公网:
一共有3个方案,分别是frp转发、ipv4独立ip端口映射、ipv6独立ip开放。
本视频后续操作是frp转发方案,如果做成一个视频,时长有点太长了。
其他方案后面会陆续出视频。
首先是第一个方案frp转发
这个方案的好处是,家庭网络不需要在路由器上做端口映射,这就意味着不需要独立ip,也不需要担心在家庭网络开放服务从而导致运营商以此为借口搞什么幺蛾子,比如警告停止提供服务等,毕竟在中国大陆,私自在家庭网络中提供服务是不被允许的,即使我们搭建这种服务的目的是自用,不会跟你讲道理的。
优点很明显,缺点当然也是有的,就是需要有一台有独立ip的服务器。同样因为国内vps价格高,带宽小。我的选择是购买cn2-gia网络的搬瓦工服务器,我在简介里放了个推荐链接,大家有需要的可以去挑选一台。
cn2与cn2-gia的区别还是很大的,gia是专用网络,任意时间段都可以有几十m的速度,基本上可以把家庭网络跑满,达到在路由器上开启端口映射直接提供服务的水平。
现在我已经准备好了一台机器,我们还需要一个域名,域名的选择比较多,有啥用啥,愿意花钱的可以考虑自行购买com域名,一年一百来块,次之是6位数xyz域名,一年10块左右,最后是不花钱的方案,去 申请一个4级域名,可是可以用的。
有了域名,把域名解析到服务器ip上,解析的做法是做一条A记录,填写一个子域名名称,例如 pan.888888.xyz,只需要填写pan,ip地址就填写自己的服务器ip。
现在准备工作已经做好了。
下一步要搭建frp了。看拓扑图。
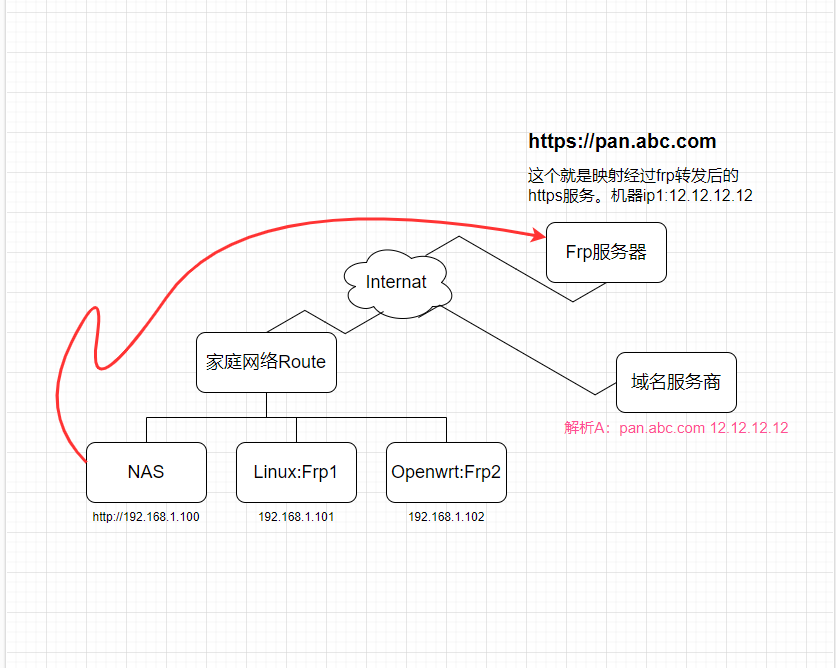
下面我们先做服务器端,在frp服务器上操作。
1、安装nginx代理工具。
nginx的作用是代理,也就是把frp转发后的端口再做一次代理,代理到80/443端口,并且挂上证书。
sudo yum update
sudo yum install nginx修改nginx配置
cd /etc/nginx/conf.d/
vi pan.conf
server {
listen 80;
server_name zhangdaqi.duckdns.org;
rewrite ^(.*) https://$server_name:443$1 permanent;
}
server {
listen 443 ssl;
server_name zhangdaqi.duckdns.org;
charset utf-8;
ssl_certificate /etc/letsencrypt/live/zhangdaqi.duckdns.org/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/zhangdaqi.duckdns.org/privkey.pem;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4;
ssl_prefer_server_ciphers on;
ssl_session_cache shared:SSL:10m;
ssl_session_timeout 5m;
keepalive_timeout 70;
index index.html index.php;
root /html/zhangdaqi.duckdns.org;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
#proxy_redirect on ;
proxy_pass http://127.0.0.1:7001;
proxy_ssl_session_reuse off;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $http_host;
# Show real IP in v2ray access.log
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}2、域名解析
在域名网站做一条解析
A记录 pan ip地址3、申请证书
我喜欢用certbot工具申请,这是Let’s Encrypt 的证书申请工具,申请到的证书有效期三个月,到期前可以进行证书更新。
安装certbot
yum install python-urllib3
yum install python-requests
yum install certbot申请证书。
certbot certonly --standalone -d pan.abc.com定时任务,自动更新证书。
修改nginx证书相关配置,完整配置类似下面,注意修改为自己的域名,以及frp端口。
现在重启nginx,就可以刷新web,实现了https。
4、搭建frp服务。
使用的操作系统是debian11
然后在我们的内网的一台机器上做frp服务,与服务器端进行数据交换。
5、openwrt配置frp
如果你有openwrt,主路由旁路由都没关系,安装frp内网穿透工具,也是可以的,配置如下。
配置nextcloud conf允许我们的域名和服务器访问。
重启服务后,理论上已经可以通过域名https访问你的nextcloud服务了,但是会报证书错误。
此为第一个方案,其他方法不久就会更新。